











Building Fast, Cost Efficient, and Accurate Retrieval for GenAI
Prototyping generative artificial intelligence applications such as search systems, retrieval augmented generation systems, or agent based architectures is relatively simple when traffic is low and accuracy is the primary concern. In production environments, however, engineering teams must balance accuracy with response speed and operating cost as systems begin handling thousands or even millions of queries each day.
This guide highlights three optimization techniques for embedding based retrieval, which is a core component of modern generative artificial intelligence systems.
Asymmetric retrieval using MongoDB Voyage four embeddings
Dimensionality reduction via Matryoshka Representation Learning
Auto quantization using MongoDB Atlas vector search
Because retrieval often runs on every query and sometimes multiple times within a single request in agent based architectures, even small inefficiencies can accumulate into significant latency and infrastructure cost.
What Is Optimized Retrieval in Generative AI Systems?
Optimized retrieval refers to improving the performance of vector search systems that power modern generative artificial intelligence applications.
In these systems, documents and queries are converted into embeddings that allow semantic similarity to be measured across large datasets. When the number of stored vectors grows or when query volume increases, retrieval performance can become a bottleneck.
Optimizing the retrieval layer ensures that generative artificial intelligence applications remain fast, accurate, and cost efficient even when operating at large scale.
Key Optimization Techniques for Embedding Based Retrieval
1. Asymmetric Retrieval
Asymmetric retrieval uses different embedding models for documents and queries while maintaining compatibility within the same embedding space.
Voyage embedding models support this approach because they operate within a shared vector space. Documents can be embedded once using a larger model such as voyage four large, while queries can be encoded using a smaller and more cost efficient model such as voyage four lite.
This strategy preserves the accuracy benefits of high capacity document embeddings while significantly reducing the cost of query embeddings. The benefit becomes especially significant for applications that process very large numbers of queries.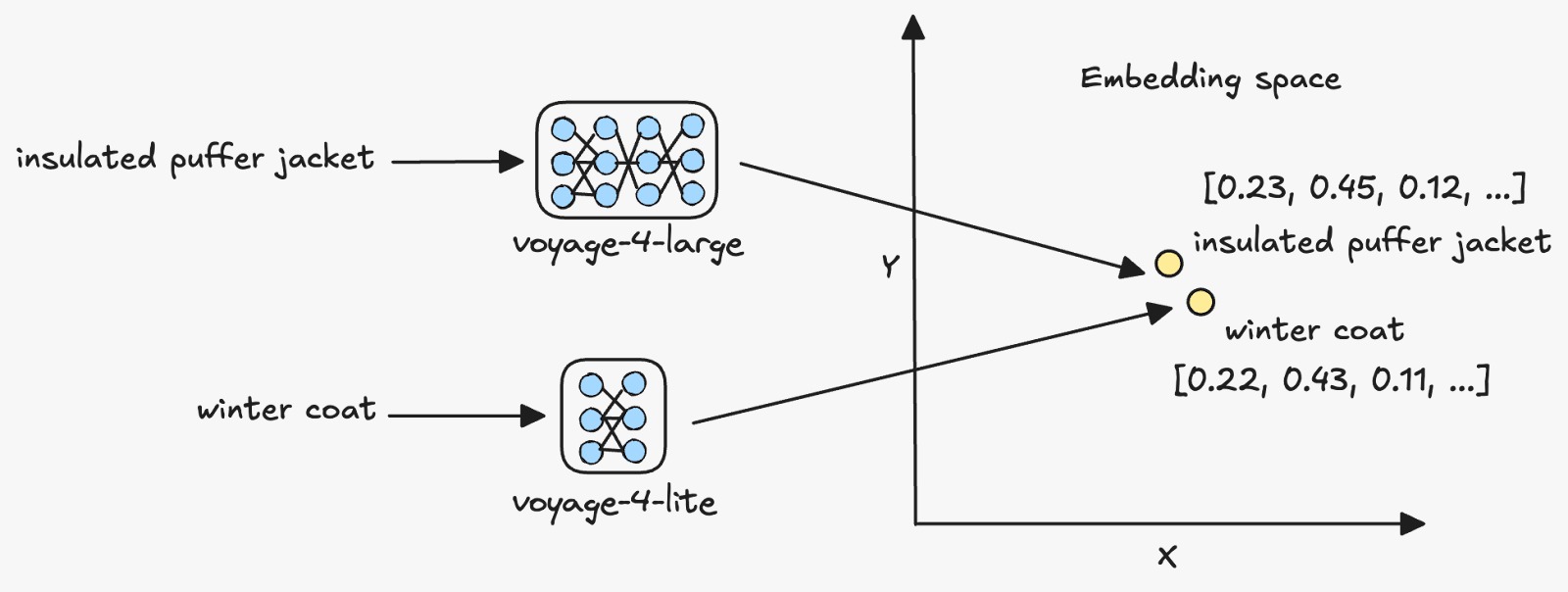
2. Vector Quantization
Vector quantization reduces the memory footprint of embeddings by compressing high precision vectors into smaller representations.
Traditional vector databases often store embeddings using float based formats that require substantial memory. Quantization converts these vectors into more compact formats such as int eight or binary representations.
MongoDB Atlas vector search supports automatic quantization in vector indexes. Full fidelity vectors remain stored on disk while compressed vectors are used in memory during search operations. The system then rescales and rescoring results to maintain retrieval quality.
This approach reduces memory consumption and improves query speed while retaining most of the original retrieval accuracy.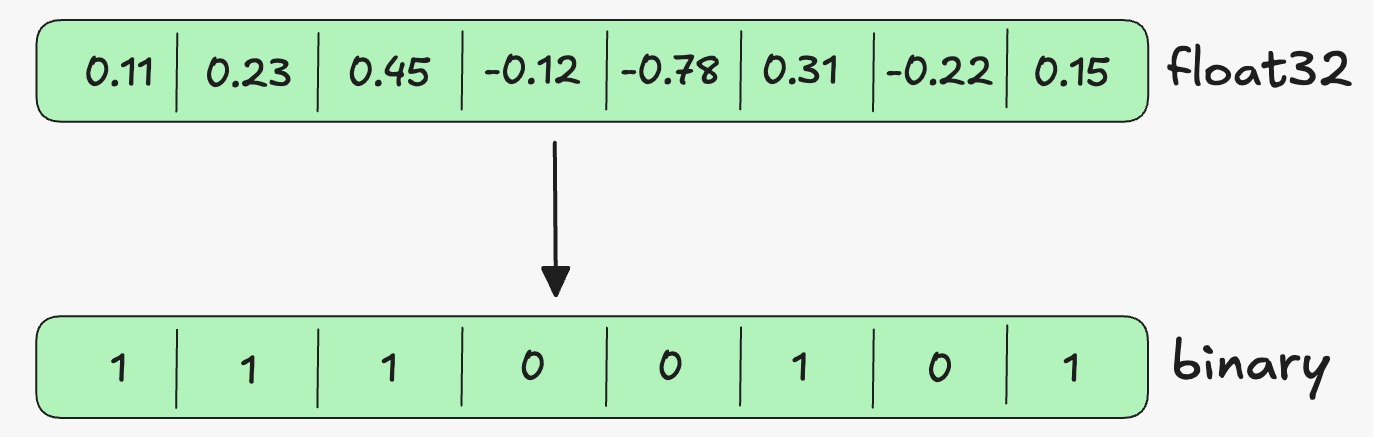
3. Dimensionality Reduction with MRL
Matryoshka Representation Learning is an embedding training technique that places the most important semantic information in the earlier dimensions of a vector.
Because of this structure, embeddings can be truncated to fewer dimensions without significantly losing semantic meaning.
Voyage embedding models support multiple dimensional configurations from the same model, including sizes such as 2048, 1024, 512, and 256 dimensions.
Reducing dimensionality lowers storage requirements, decreases memory usage during vector search, and improves overall query latency.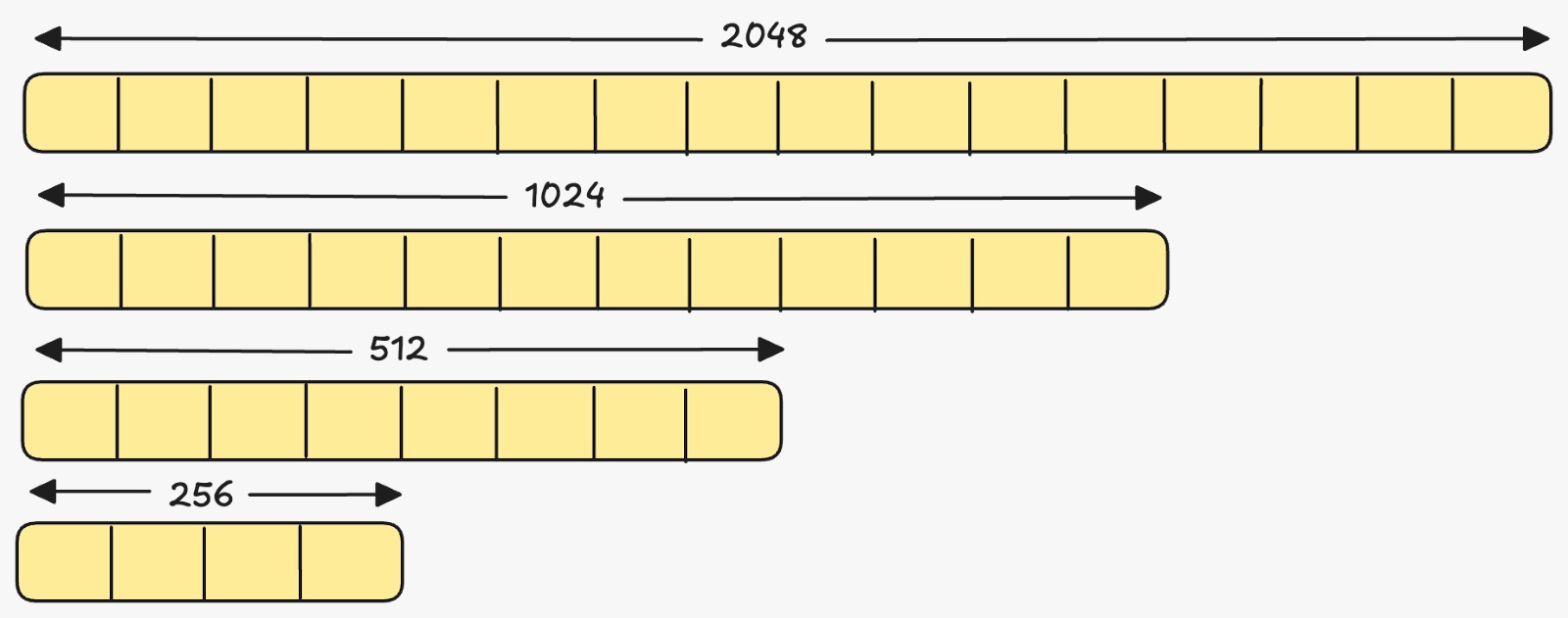
When to Use Each Technique
These techniques are complementary and can be combined depending on the bottleneck:
An evaluation on the NFCorpus dataset showed:
All three optimizations retain approximately 98–99% of baseline retrieval accuracy.
Binary quantization improves query latency by about 60% and reduces vector search memory usage by 96%.
Dimensionality reduction from 1024 to 512 dimensions delivers ~40% faster queries and cuts storage and memory by 50%.
Asymmetric retrieval halves query embedding costs with minimal impact on retrieval quality.
Illustrative Voyage 4 pricing analysis shows that as daily queries grow from 10,000 to 1 million, annual savings from asymmetric retrieval can exceed $1 million when using voyage‑4‑lite for queries instead of voyage‑4‑large.
Business teams should prioritize optimizations based on their main constraint: latency‑sensitive applications will benefit most from quantization and dimensionality reduction, while cost‑sensitive, high‑volume applications should consider asymmetric retrieval.
Key Takeaways for Building Scalable GenAI Retrieval Systems
Organizations deploying generative artificial intelligence applications should evaluate the performance characteristics of their retrieval pipelines carefully.
Retrieval processes operate on nearly every query and directly influence both system responsiveness and operational cost. Optimizing retrieval pipelines through dimensionality reduction, quantization, and asymmetric retrieval enables teams to maintain fast response times while controlling infrastructure expenses.
Applications that prioritize low latency will benefit most from dimensionality reduction and quantization. Systems that process very large volumes of queries should prioritize asymmetric retrieval to reduce embedding generation costs.
Combining these techniques allows teams to build scalable generative artificial intelligence systems that remain both accurate and efficient.
Frequently Asked Questions
What is optimized retrieval in generative artificial intelligence systems?
Optimized retrieval refers to techniques that improve how vector databases retrieve relevant documents while reducing latency, memory usage, and infrastructure cost.
What is asymmetric retrieval?
Asymmetric retrieval is a method where documents and queries are embedded using different models that share the same embedding space. Larger models can encode documents while smaller models encode queries to reduce cost.
What is vector quantization?
Vector quantization compresses embeddings into smaller representations that require less memory. This allows vector search systems to run faster while preserving most retrieval accuracy.
What is Matryoshka Representation Learning?
Matryoshka Representation Learning is an embedding technique where the most important semantic information is captured in earlier vector dimensions, allowing embeddings to be shortened without significant information loss.
